
IT-Leiter und Datenschutzbeauftragte stehen vor derselben Frage: Wir wollen KI einsetzen, aber können wir uns auf einen US-Anbieter verlassen? Gibt es europäische Alternativen? Was passiert, wenn sich die politische Lage ändert?
Die ehrliche Antwort ist unbequem: Es gibt derzeit keine europäischen Sprachmodelle, die mit den führenden US-Anbietern konkurrieren können. Aber die Frage ist falsch gestellt. Die eigentliche Entscheidung ist nicht "welcher Anbieter", sondern "über welchen Weg beziehe ich die gleichen Modelle". Und die Architektur, die dahinter steht, bestimmt, ob ein Unternehmen abhängig bleibt oder jederzeit wechseln kann.
Europäische Sprachmodelle können derzeit nicht mithalten
Das ist kein vorübergehender Zustand, sondern eine strukturelle Realität. Open-Source-Modelle, die auf eigenen Servern laufen könnten, liegen rund anderthalb Jahre hinter dem Stand der Technik. Diese Einschätzung hat sich über 18 Monate hinweg nicht verändert: Der Rückstand ist nicht schrumpfend, sondern stabil.
Das bedeutet: Wer die führende Qualität will, kommt an den kommerziellen Modellen der großen Anbieter nicht vorbei. OpenAI, Google (Gemini) und Anthropic (Claude) liefern die Modelle, die in der Praxis die besten Ergebnisse erzielen, insbesondere bei komplexen Aufgaben, die Reasoning und mehrstufige Verarbeitung erfordern.
Das bedeutet nicht, dass On-Premise-Lösungen generell sinnlos sind. Für einfache Aufgaben wie interne Dokumentenrecherche, Transkription von Meetings oder unkomplexe Wissensabfragen können Open-Source-Modelle durchaus ausreichen. Aber für anspruchsvolle Fachfragen, iterative Datenabfragen oder Aufgaben, die echtes "Nachdenken" des Modells erfordern, braucht man die führenden Modelle. Die Entscheidung ist: führende Qualität oder vollständige Kontrolle über die Infrastruktur. Beides gleichzeitig ist heute nicht realistisch.
Die eigentliche Frage: Bezugsweg, nicht Anbieter
Wenn die Modelle der großen Anbieter die beste Wahl sind, lautet die nächste Frage: Wie beziehe ich sie?
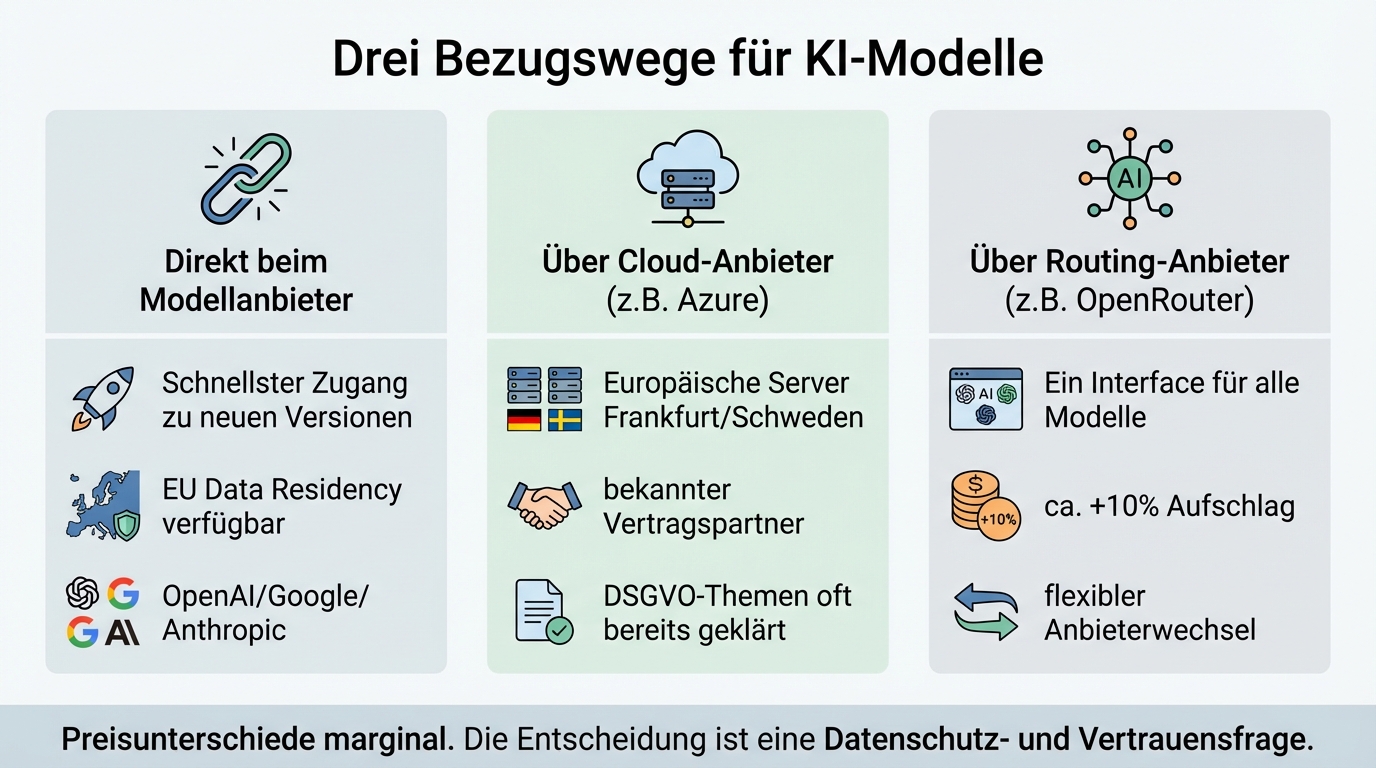
Drei Wege stehen zur Verfügung:
Direkt beim Modellanbieter. OpenAI, Google und Anthropic bieten API-Zugang zu ihren Modellen an. OpenAI bietet inzwischen auch für Business-Kunden europäische Datenresidenz an, ohne ein Enterprise-Agreement abschließen zu müssen. Der direkte Zugang ist in der Regel schneller bei neuen Modellversionen und besser verfügbar.
Über einen etablierten Cloud-Anbieter. Microsoft Azure hostet die OpenAI-Modelle auf europäischen Servern, beispielsweise in Frankfurt, Schweden oder der Schweiz. Google Cloud bietet Ähnliches für Gemini. Der Vorteil: In der Datenschutzerklärung steht "Microsoft" oder "Google", nicht "OpenAI aus San Francisco". Für Unternehmen mit sensiblen Stakeholdern kann das den entscheidenden Unterschied machen.
Über spezialisierte Routing-Anbieter. Dienste wie OpenRouter bündeln den Zugang zu verschiedenen Modellen über eine einheitliche API. Der Aufschlag liegt bei rund 10 Prozent auf die API-Kosten. Der Vorteil: ein einziger Vertrag, ein einziges Interface für alle Modelle, und bei manchen Anbietern die Möglichkeit, europäische Server zu wählen.
Die Preisunterschiede zwischen diesen Bezugswegen sind marginal. OpenAI direkt und Azure haben sehr vergleichbare Kosten. Die Bezugswegfrage ist eine Datenschutz- und Vertrauensfrage, keine Kostenfrage. On-Premise ist strukturell teurer, wegen nicht ausgelasteter Hardware, hoher Energiepreise und Fixkosten für den Betrieb.
Azure ist oft die politisch klügere Wahl
Aus rein technischer Sicht wäre der direkte API-Zugang beim Modellanbieter die beste Option: schneller bei neuen Versionen, bessere Verfügbarkeit, weniger Zwischenschichten. Aber Technik ist nicht alles.
20 bis 30 Prozent der Stakeholder in deutschen Unternehmen reagieren stark auf den Namen in der Datenschutzerklärung. "OpenAI Limited, San Francisco" löst Diskussionen aus, unabhängig davon, ob die Daten tatsächlich in den USA verarbeitet werden. "Microsoft, Frankfurt" löst diese Diskussionen nicht aus, weil die meisten Unternehmen bereits eine etablierte Geschäftsbeziehung mit Microsoft haben und DSGVO-Themen mit dem Konzern längst geklärt sind.
Für Unternehmen mit hohen Vertraulichkeitsanforderungen ist Azure daher oft die pragmatisch bessere Empfehlung, auch wenn sie technisch einen kleinen Nachteil mit sich bringt. Der Name in der Datenschutzerklärung ist ein realer Faktor in der internen und externen Kommunikation.
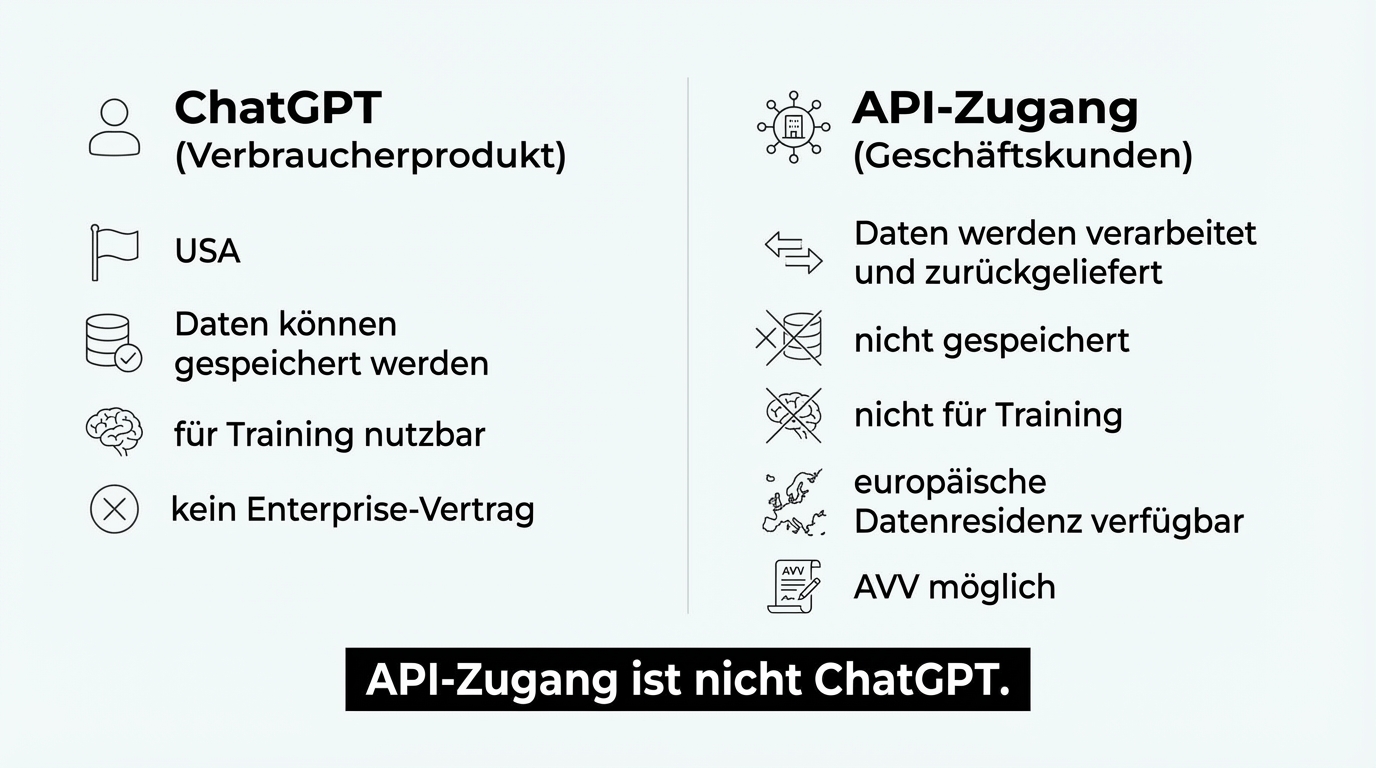
Wichtig dabei: Azure-gehostete Modelle sind nicht ChatGPT. Die Anwendung ChatGPT läuft in den USA und ist ein Verbraucherprodukt. Der API-Zugang zum reinen Modell (GPT) über Azure ist etwas vollkommen anderes: ein DSGVO-konformer Dienst, bei dem die Daten in der gewählten Region bleiben und nicht für das Training des Modells verwendet werden.
Modell-Agnostik ist keine theoretische Versicherung, sondern gelebte Praxis
Die Angst vor Abhängigkeit von einem einzelnen Anbieter ist berechtigt. Die Lösung liegt nicht darin, auf schwächere Alternativen auszuweichen, sondern in einer Architektur, die den Anbieter austauschbar macht.
Das Prinzip: Die eigentliche Software ist vom Modell entkoppelt. Das Sprachmodell ist ein austauschbares Modul, das über eine standardisierte Schnittstelle angebunden wird. Ob dahinter GPT, Gemini oder Claude arbeitet, ist eine Konfigurationsfrage, kein Architekturproblem.
In der Praxis wird ungefähr die Hälfte der Projekte direkt über OpenAI betrieben, die andere Hälfte über Azure. Es gibt Kunden, die verschiedene Modelle verschiedener Hersteller einsetzen, je nach Aufgabe. Und ja, es wurde in laufenden Projekten das Modell gewechselt. Bei gut geschriebenen Konfigurationen liegt der Aufwand für einen Modellwechsel bei ein bis zwei Wochen Anpassungsarbeit, und zwar auf der Inhaltsseite (Formulierungen optimieren), nicht auf der technischen Seite.
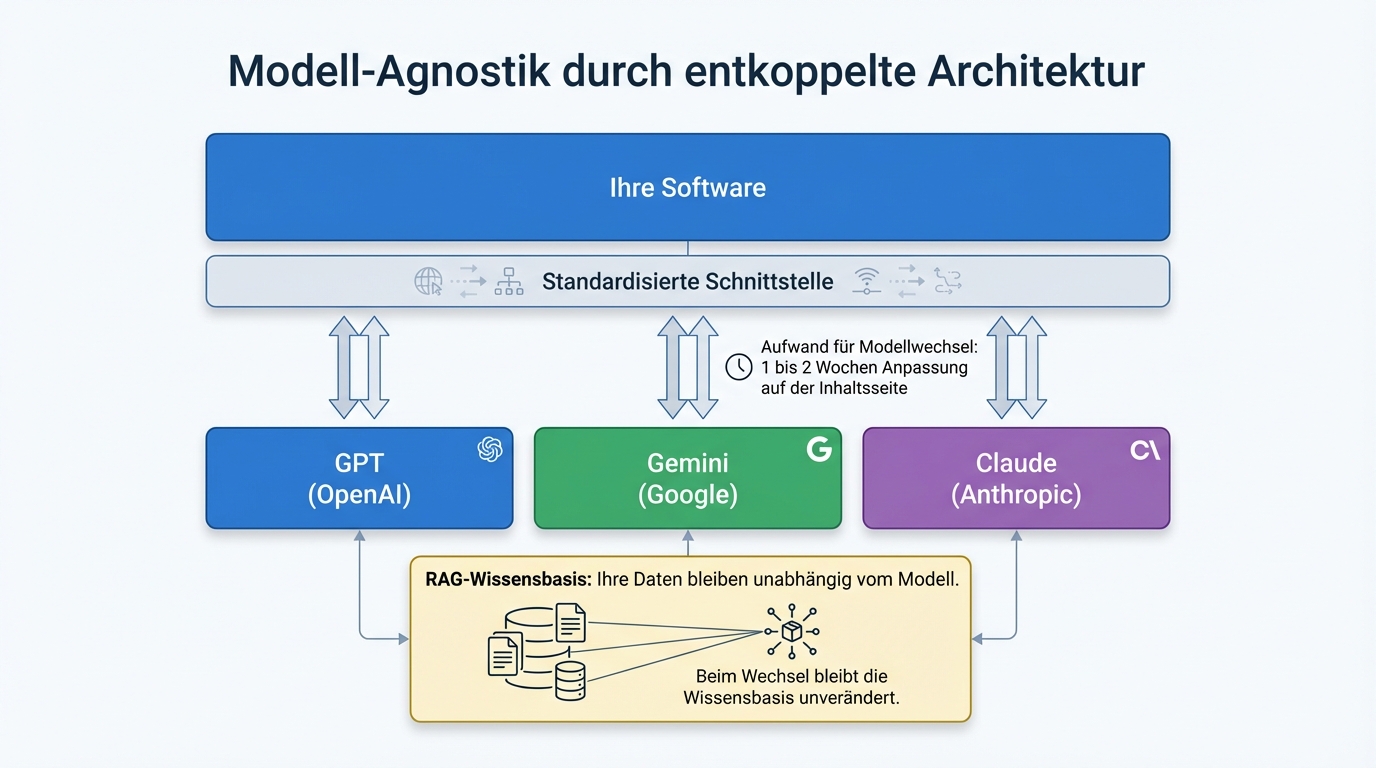
Diese Modell-Agnostik ist auch eine Risikostrategie: Wenn das Vertrauen in einen Anbieter verloren geht, ob durch einen Datenschutzskandal, eine Preiserhöhung oder eine politische Entscheidung, ist der Wechsel jederzeit möglich. Kein Vendor Lock-in, keine existenzielle Abhängigkeit.
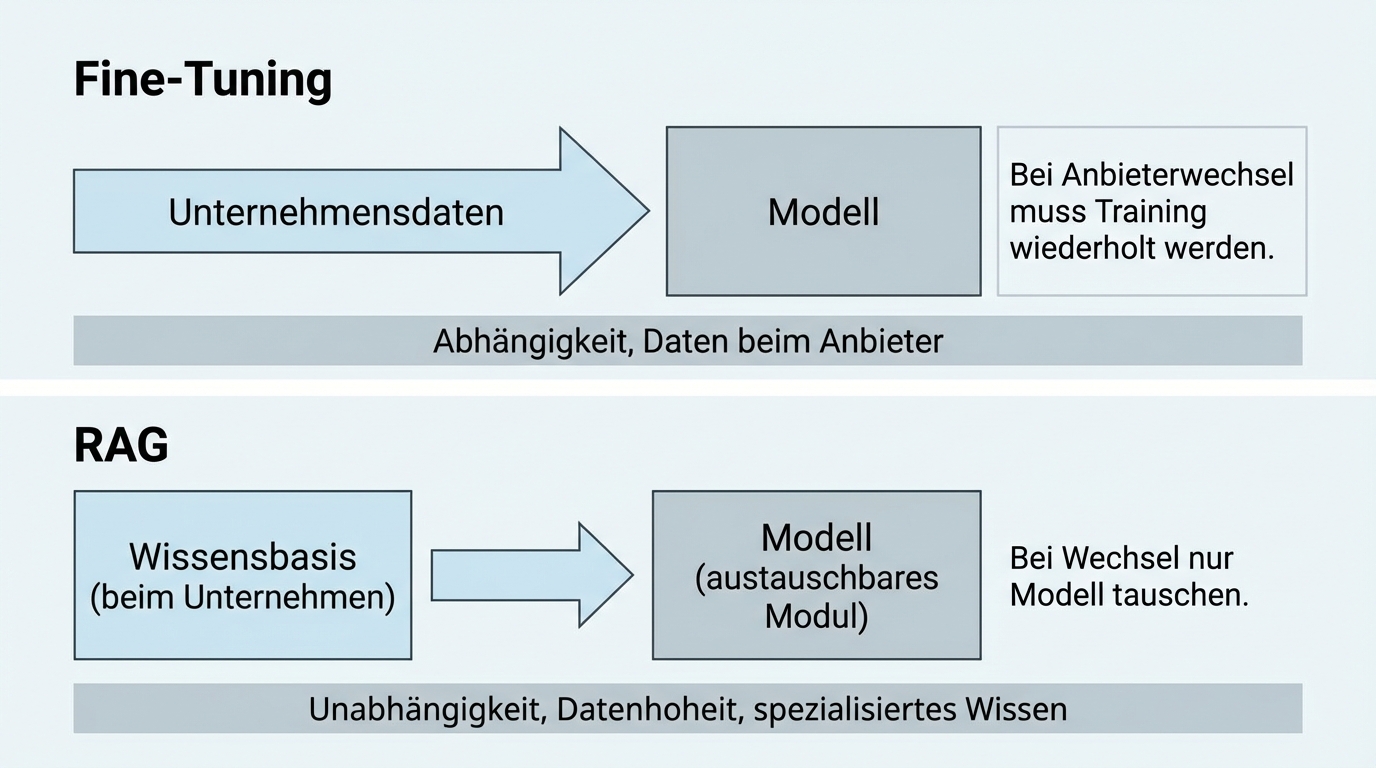
RAG statt Fine-Tuning: Die Architektur, die Unabhängigkeit ermöglicht
Der Schlüssel zur Modell-Agnostik liegt in der Architektur. Statt ein Sprachmodell mit eigenen Daten nachzutrainieren (Fine-Tuning), wird eine sogenannte RAG-Architektur eingesetzt: Die eigenen Daten bleiben in einer separaten, durchsuchbaren Wissensbasis. Bei jeder Anfrage werden die relevanten Informationen aus dieser Wissensbasis geholt und dem Modell als Kontext mitgegeben.
Drei Vorteile, die direkt mit der Anbieterfrage zusammenhängen:
Keine Abhängigkeit vom Modellhersteller. Beim Fine-Tuning wird das Modell selbst verändert. Wer den Anbieter wechselt, muss das Training wiederholen. Bei RAG bleibt die Wissensbasis unverändert, nur das Modell wird ausgetauscht.
Datenhoheit bleibt beim Unternehmen. Die eigenen Dokumente werden nicht an den Modellanbieter geschickt, um dort ins Training einzufließen. Sie bleiben in der eigenen Infrastruktur oder bei einem gewählten Hoster.
Spezialisiertes Wissen ohne Nachtraining. Die RAG-Architektur liefert validiertes Fachwissen mit nachvollziehbaren Quellenangaben. ChatGPT kennt keine internen Vorschriften, keine unveröffentlichten Gutachten, keine firmenspezifischen Prozesse. Ein RAG-System schon.
In der Weiterentwicklung arbeiten RAG und die neuen Reasoning-Fähigkeiten der Modelle zusammen: RAG liefert den Kontext, das Reasoning-Modul arbeitet darauf. Die Austauschbarkeit bleibt erhalten, weil die Kernfähigkeiten (Reasoning, automatisierte Werkzeugnutzung) bei allen zwei bis drei führenden Anbietern vorhanden sind.
Was "datenschutzkonform" in der Praxis bedeutet
Die DSGVO-Debatte bei KI-Lösungen wird oft emotional statt sachlich geführt. Drei Punkte schaffen Klarheit:
API-Zugang ist nicht ChatGPT. Wer die API eines Modellanbieters nutzt, sendet Daten an einen Dienst, der sie verarbeitet und das Ergebnis zurückliefert. Die Daten werden nicht gespeichert und nicht für das Training verwendet. Das ist ein fundamental anderer Vorgang als die Nutzung von ChatGPT als Verbraucherprodukt.
Europäische Datenresidenz ist verfügbar. Sowohl Azure als auch OpenAI Business bieten inzwischen die Möglichkeit, Daten ausschließlich auf europäischen Servern zu verarbeiten. Die Einschränkung, dass dafür ein Enterprise-Vertrag nötig war, hat sich durch die Marktentwicklung aufgelöst.
Selbst hosten ist kein Sicherheitsgewinn. Wer argumentiert, On-Premise sei sicherer, unterstellt, dass die eigene IT-Security-Abteilung kompetenter ist als die der großen Cloud-Anbieter. Für die meisten mittelständischen Unternehmen ist das eine fragwürdige Annahme. Die vertrauenswürdigste Option ist oft der Cloud-Anbieter, dem man am meisten vertraut, kombiniert mit einer Architektur, die den Wechsel jederzeit ermöglicht.
Was die Entscheidung erfordert
Die Modellwahl ist keine existenzielle Entscheidung. Sie ist eine pragmatische Abwägung, die in zwei Wochen getroffen werden kann. Drei Fragen reichen:
Wie sensibel sind Ihre Stakeholder? Wenn 20 Prozent Ihrer Mitglieder, Kunden oder Mitarbeiter auf "OpenAI, San Francisco" in der Datenschutzerklärung reagieren, nehmen Sie Azure oder einen europäischen Hoster. Der technische Nachteil ist minimal, der politische Vorteil erheblich.
Wie komplex sind Ihre Aufgaben? Für einfache Dokumentenrecherche und Transkription kann On-Premise ausreichen. Für Fachfragen mit Reasoning, mehrstufiger Verarbeitung und automatisierter Werkzeugnutzung brauchen Sie die führenden Cloud-Modelle.
Wie wichtig ist Ihnen Unabhängigkeit? Eine modell-agnostische Architektur mit RAG statt Fine-Tuning gibt Ihnen die Freiheit, jederzeit den Anbieter zu wechseln. Das kostet im Aufbau nicht mehr, sichert aber langfristig gegen Abhängigkeit ab.