
IT managers and data protection officers face the same question: we want to use AI, but can we rely on a US provider? Are there European alternatives? What happens if the political landscape shifts?
The honest answer is uncomfortable: there are currently no European language models that can compete with the leading US providers. But the question is framed wrong. The real decision isn't "which provider" but "through which channel do I access the same models." And the architecture behind it determines whether a company stays dependent or can switch at any time.
European language models cannot keep up right now
This is not a temporary state but a structural reality. Open-source models that could run on your own servers are roughly eighteen months behind the state of the art. This assessment has remained unchanged over 18 months: the gap is not shrinking, it's stable.
That means: if you want leading quality, you cannot avoid the commercial models from the major providers. OpenAI, Google (Gemini), and Anthropic (Claude) deliver the models that produce the best results in practice, especially for complex tasks that require reasoning and multi-step processing.
That doesn't mean on-premise solutions are pointless across the board. For simple tasks like internal document search, meeting transcription, or straightforward knowledge queries, open-source models can be sufficient. But for demanding domain questions, iterative data queries, or tasks that require genuine "thinking" from the model, you need the leading models. The decision is: leading quality or full control over the infrastructure. Both at once is not realistic today.
The real question: procurement channel, not provider
If the major providers' models are the best choice, the next question is: how do I access them?
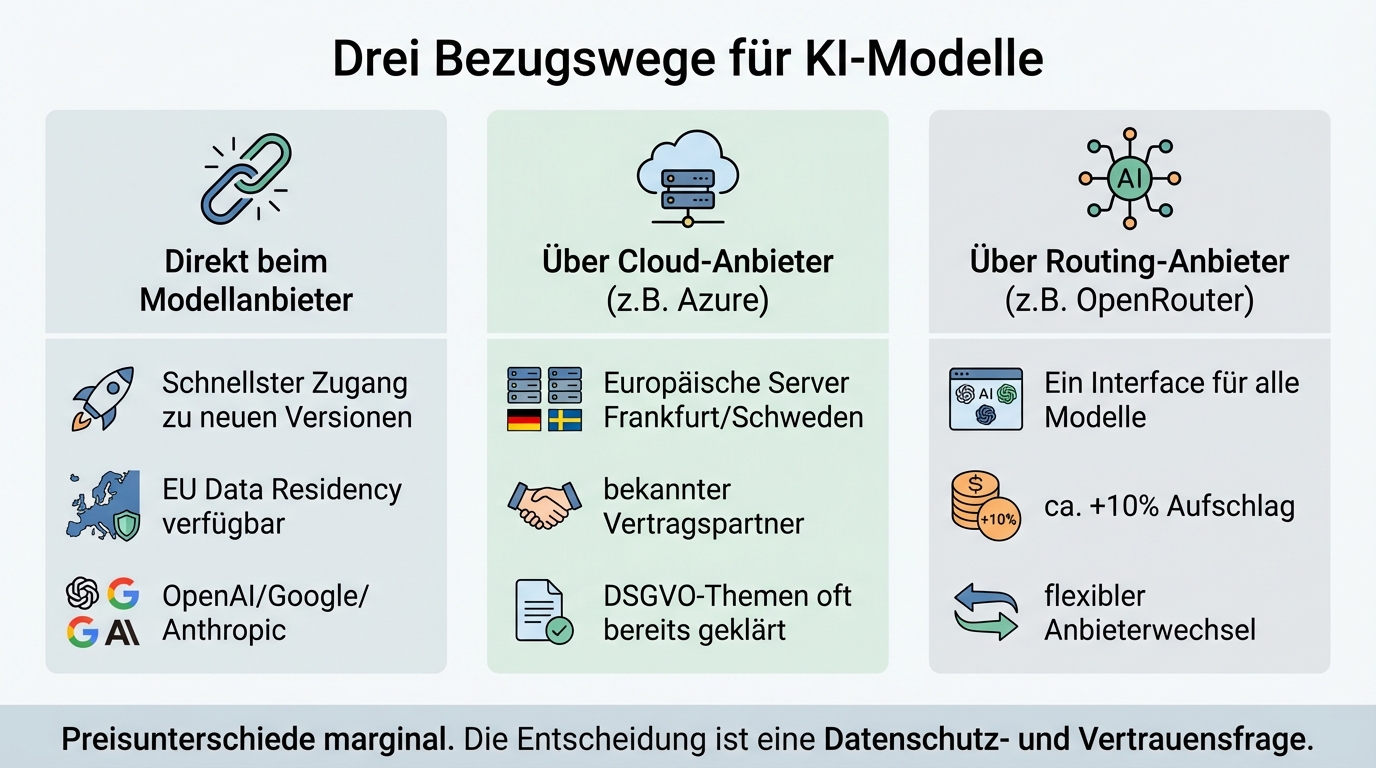
Three channels are available:
Directly from the model provider. OpenAI, Google, and Anthropic offer API access to their models. OpenAI now also offers European data residency for business customers without requiring an enterprise agreement. Direct access is typically faster for new model versions and offers better availability.
Through an established cloud provider. Microsoft Azure hosts the OpenAI models on European servers, for example in Frankfurt, Sweden, or Switzerland. Google Cloud offers something similar for Gemini. The advantage: the data processing agreement says "Microsoft" or "Google," not "OpenAI from San Francisco." For companies with sensitive stakeholders, that can make the decisive difference.
Through specialised routing providers. Services like OpenRouter bundle access to various models through a unified API. The surcharge is around 10 percent on API costs. The advantage: a single contract, a single interface for all models, and with some providers the option to select European servers.
Price differences between these channels are marginal. OpenAI direct and Azure have very comparable costs. The channel question is a data protection and trust question, not a cost question. On-premise is structurally more expensive due to underutilised hardware, high energy prices, and fixed operating costs.
Azure is often the politically smarter choice
From a purely technical standpoint, direct API access from the model provider would be the best option: faster for new versions, better availability, fewer intermediate layers. But technology isn't everything.
20 to 30 percent of stakeholders in German companies react strongly to the name in the data processing agreement. "OpenAI Limited, San Francisco" triggers discussions, regardless of whether the data is actually processed in the US. "Microsoft, Frankfurt" doesn't trigger those discussions, because most companies already have an established business relationship with Microsoft and have long since resolved GDPR matters with the corporation.
For companies with high confidentiality requirements, Azure is therefore often the more pragmatic recommendation, even though it comes with a small technical drawback. The name in the data processing agreement is a real factor in internal and external communication.
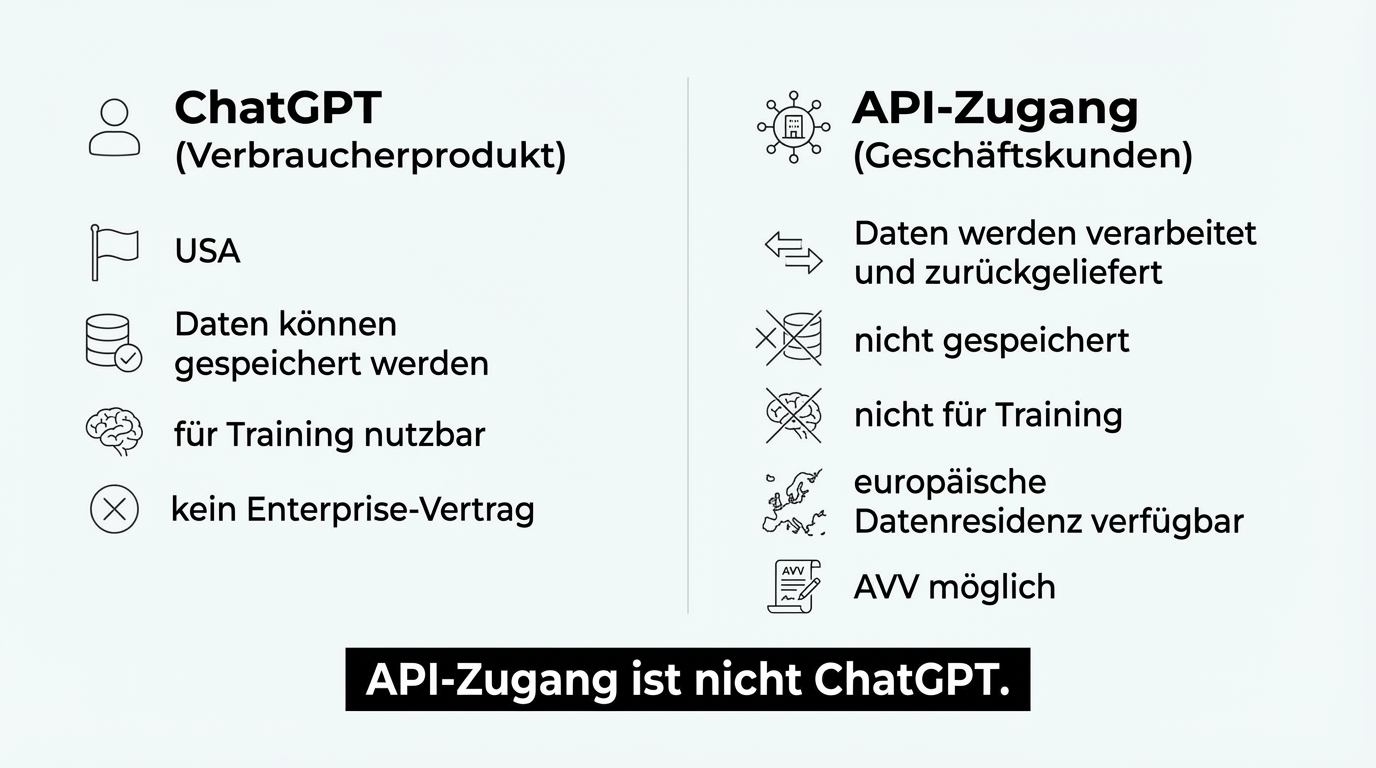
Important to note: Azure-hosted models are not ChatGPT. The ChatGPT application runs in the US and is a consumer product. API access to the underlying model (GPT) via Azure is something entirely different: a GDPR-compliant service where data stays in the chosen region and is not used for model training.
Model agnosticism is not a theoretical safeguard but lived practice
The fear of depending on a single provider is justified. The solution is not to fall back on weaker alternatives, but to adopt an architecture that makes the provider interchangeable.
The principle: the actual software is decoupled from the model. The language model is a replaceable module connected through a standardised interface. Whether GPT, Gemini, or Claude runs behind it is a configuration question, not an architectural problem.
In practice, roughly half of all projects run directly through OpenAI, the other half through Azure. Some clients use different models from different providers depending on the task. And yes, models have been switched in running projects. With well-written configurations, switching a model takes one to two weeks of adjustment work, specifically on the content side (optimising prompts), not on the technical side.
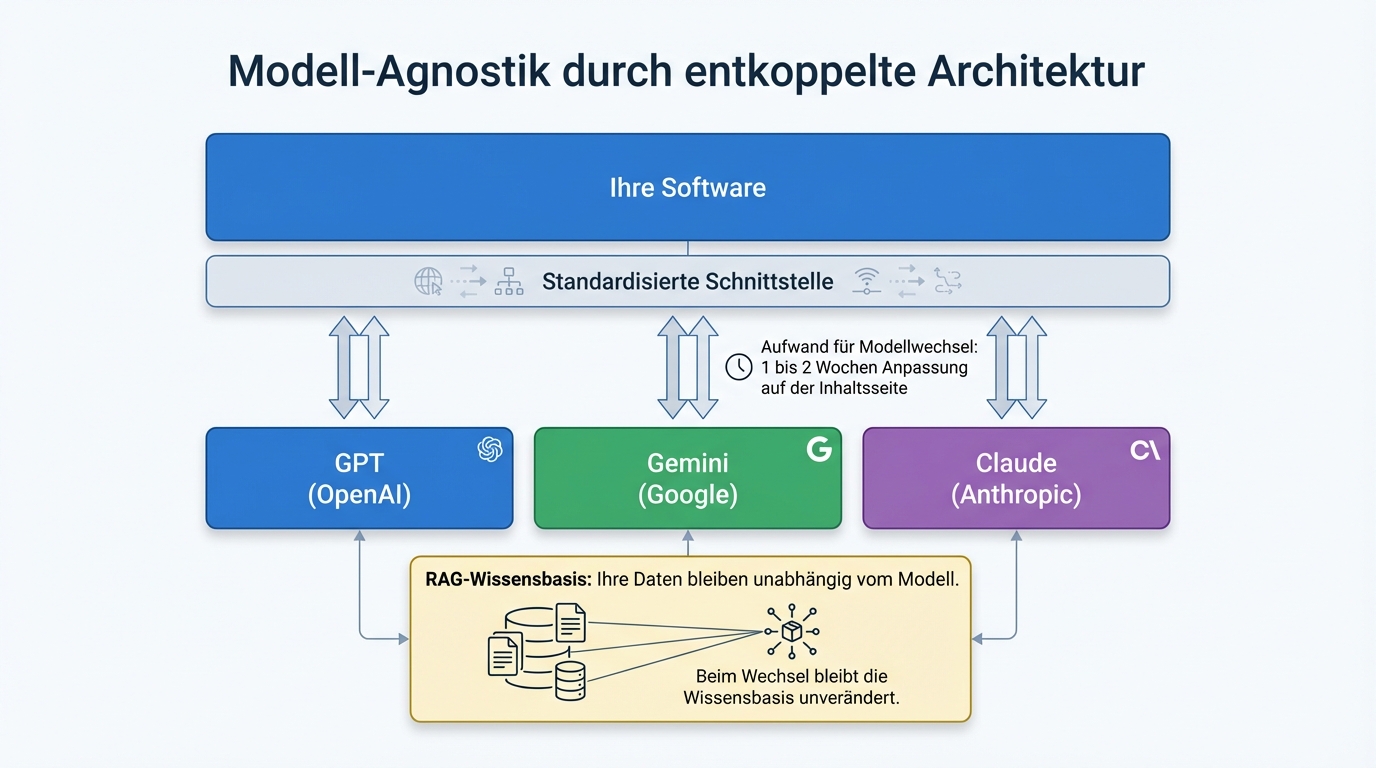
This model agnosticism is also a risk strategy: if trust in a provider is lost, whether through a data protection scandal, a price increase, or a political decision, switching is possible at any time. No vendor lock-in, no existential dependency.
RAG instead of fine-tuning: the architecture that enables independence
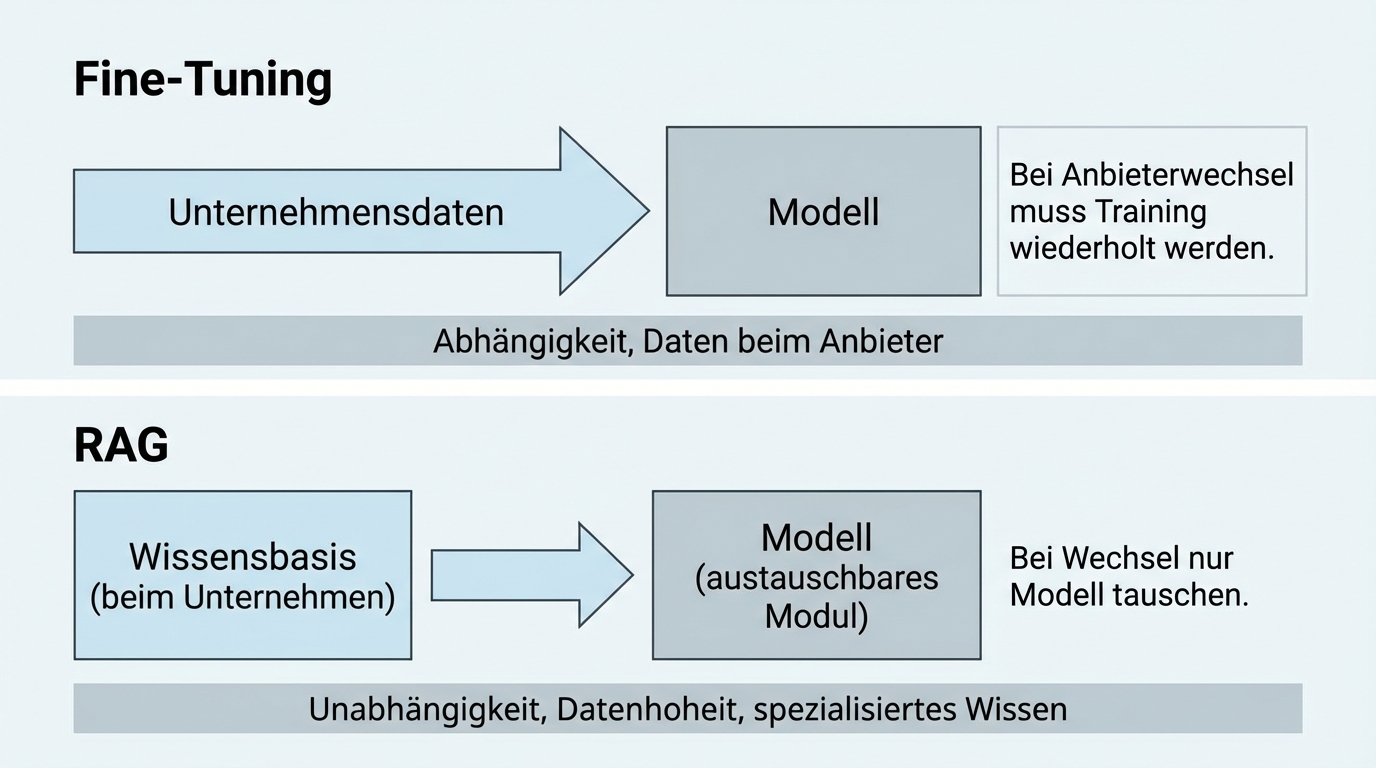
The key to model agnosticism lies in the architecture. Instead of retraining a language model with your own data (fine-tuning), a RAG architecture is used: your own data stays in a separate, searchable knowledge base. With every query, the relevant information is retrieved from this knowledge base and passed to the model as context.
Three advantages that relate directly to the provider question:
No dependency on the model vendor. With fine-tuning, the model itself is modified. If you switch providers, you have to repeat the training. With RAG, the knowledge base remains unchanged; only the model is swapped.
Data sovereignty stays with the company. Your own documents are not sent to the model provider to be incorporated into training. They remain in your own infrastructure or with a chosen host.
Specialised knowledge without retraining. The RAG architecture delivers validated domain knowledge with traceable source references. ChatGPT doesn't know your internal regulations, unpublished assessments, or company-specific processes. A RAG system does.
As models evolve, RAG and the new reasoning capabilities work together: RAG provides the context, the reasoning module operates on it. Interchangeability is preserved because the core capabilities (reasoning, automated tool use) are present across all two to three leading providers.
What "GDPR-compliant" means in practice
The GDPR debate around AI solutions is often emotional rather than factual. Three points bring clarity:
API access is not ChatGPT. When you use a model provider's API, you send data to a service that processes it and returns the result. The data is not stored and not used for training. That is a fundamentally different operation from using ChatGPT as a consumer product.
European data residency is available. Both Azure and OpenAI Business now offer the option to process data exclusively on European servers. The restriction that this required an enterprise agreement has been resolved by market developments.
Self-hosting is not a security advantage. Those who argue that on-premise is more secure are assuming their own IT security team is more competent than those of the major cloud providers. For most mid-market companies, that is a questionable assumption. The most trustworthy option is often the cloud provider you trust most, combined with an architecture that allows switching at any time.
What the decision requires
Choosing a model is not an existential decision. It is a pragmatic trade-off that can be made in two weeks. Three questions are enough:
How sensitive are your stakeholders? If 20 percent of your members, clients, or employees react to "OpenAI, San Francisco" in the data processing agreement, choose Azure or a European host. The technical disadvantage is minimal, the political advantage substantial.
How complex are your tasks? For simple document search and transcription, on-premise may suffice. For domain questions with reasoning, multi-step processing, and automated tool use, you need the leading cloud models.
How important is independence to you? A model-agnostic architecture with RAG instead of fine-tuning gives you the freedom to switch providers at any time. It costs no more to build but secures you against long-term dependency.