
German companies want to use AI. The technology is mature, the use cases are clear, competitive pressure is mounting. And then the question comes up: What about data privacy?
In many organisations, that question brings everything to a halt. The data protection officer says "I need to review this." IT says "on-premise would be safer." Management says "let's wait and see." Months pass. Nothing happens.
That's unnecessary. Build the infrastructure correctly and 90 percent of the data protection challenge is solved. Not through legal opinions, but through architecture.
Most data privacy concerns are infrastructure problems
When companies ask "Are we allowed to do this?", what they usually mean is: Can our employee data, customer data, and business figures sit on someone else's servers? Will they be used for training? Who has access?
These are legitimate questions. But they are not legal questions that require a lawyer. They are technical questions that can be answered by choosing the right infrastructure.
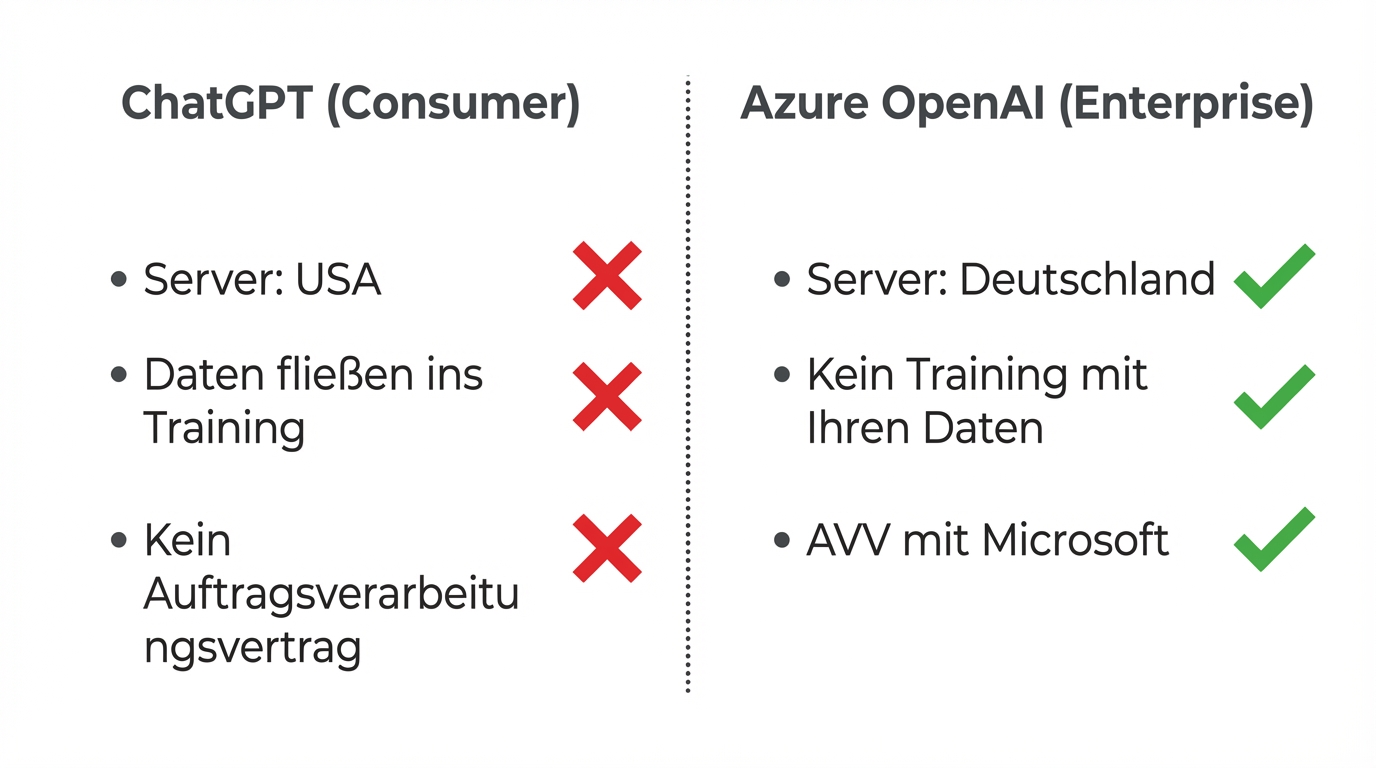
The core point: there is a fundamental difference between ChatGPT, the consumer product, and Azure OpenAI, the enterprise infrastructure. ChatGPT runs on American servers. Private accounts feed data into training. For business purposes, that's not an option.
Azure OpenAI is something entirely different. The same models (GPT-4, GPT-4o) run on Microsoft servers in German data centres. No data flows into training. Microsoft's access is contractually limited to technical troubleshooting. The contract structure is identical to the one your company has most likely already accepted for Office 365 or Azure Cloud.
That's the decisive point: if you already use Microsoft products, you've essentially already made the data privacy decision. Azure OpenAI operates under the same legal and technical framework.
Why on-premise is almost always the wrong path
The intuitive reaction of many IT leaders: if data privacy is the problem, we'll host it ourselves. Our own servers, our own models, full control.
That sounds reasonable. In practice, it's usually the most expensive and worst solution.
On-premise AI means open-source models like Llama, KIMI, or QWEN. These models are improving month by month. But today they still lag significantly behind the proprietary models from OpenAI and Anthropic. What works reliably with GPT-4o frequently produces errors with open-source models -- errors that are more costly than the supposed data privacy advantage.
Then there's the hardware: at least 100,000 euros for a usable GPU cluster, 1 TB of RAM, ongoing maintenance, model updates, specialised staff. A competitor running a GPU cluster in their basement is, in our experience, 20 versions behind the state of the art.
On-premise is justified in exactly one case: absolute secrecy. Defence industry. Intelligence agencies. Scenarios where even a contractually secured cloud solution is politically unacceptable.
For everyone else: the combination of Azure hosting in Germany, contractual safeguards, and deliberate system design provides more security than a self-hosted server, at a fraction of the cost.
The three pillars: what GDPR-compliant AI looks like in practice
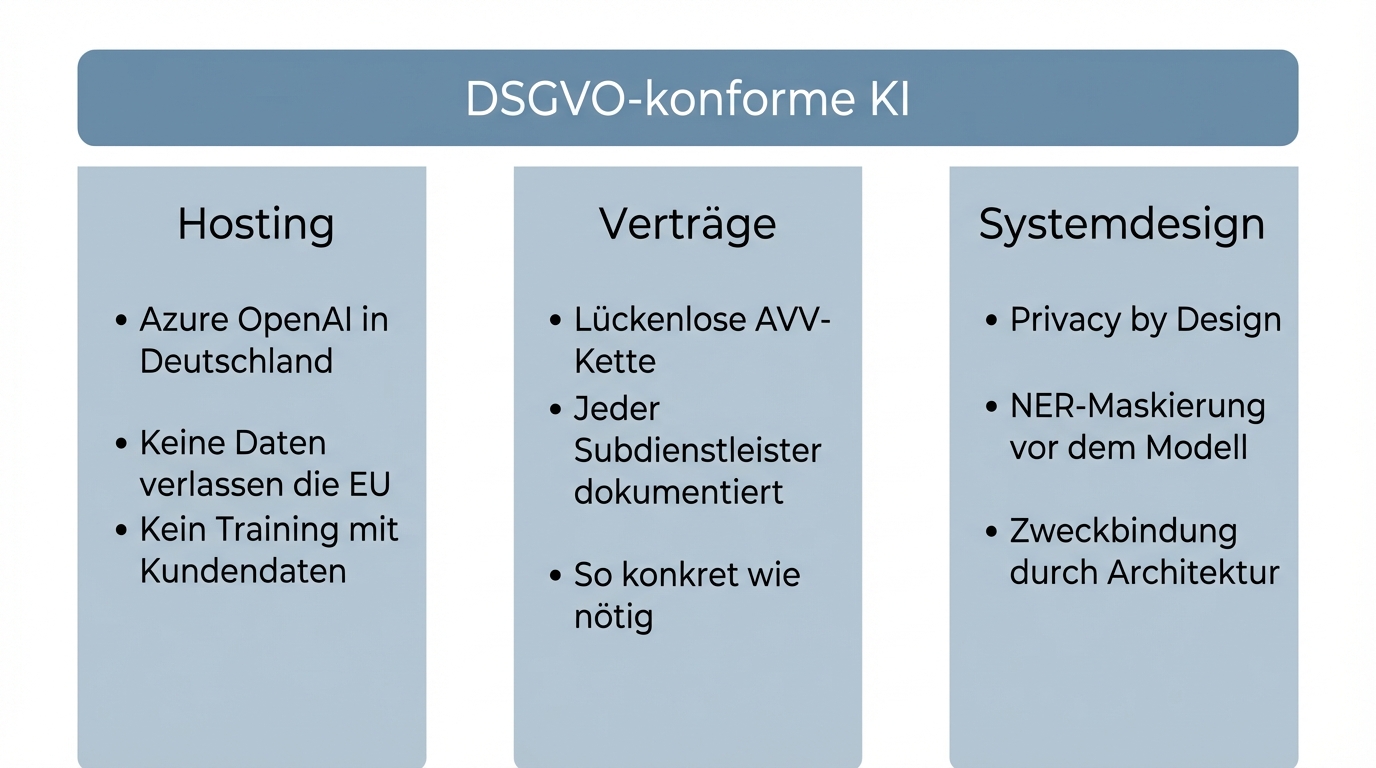
GDPR-compliant AI rests on three pillars. Each one is necessary on its own; together they are sufficient.
1. Hosting and infrastructure: German servers, clear boundaries
- Azure OpenAI on German servers: Models run in German data centres. No data leaves the EU.
- No training with your data: Contractually excluded. Your business data does not flow into model updates.
- Microsoft access: Limited to technical troubleshooting, contractually fixed. Same logic as Office 365.
In practice, this contractual safeguard is sufficient for the vast majority of companies. If you already use Microsoft products like Office 365, you've essentially already accepted this framework agreement. Azure OpenAI is the pragmatic gold standard.
2. Contracts and DPA chain: complete and transparent
Every service provider in the chain needs a Data Processing Agreement (DPA). That sounds bureaucratic, but in practice it's manageable when you set it up correctly from the start.
A typical DPA chain looks like this: your company signs a DPA with the implementation partner. The implementation partner has DPAs with its subcontractors. Each contract documents where data resides and who has access.
Example from a real project: client, implementation partner, Langfuse (monitoring), AWS (hosting), ClickHouse (database). Every link contractually secured, every link transparently documented.
An important note: contracts should be as specific as necessary and as abstract as possible. If you write every implementation detail into the DPA, you need a contract amendment for every technical change. That's neither practical nor necessary.
3. System design: privacy by design instead of retrospective safeguards
The third pillar is the most important, because it technically enforces what contracts only promise.
- Pseudonymisation: Customer IDs instead of real names. Where possible, the AI model never sees personal data.
- Local NER models: Named Entity Recognition detects and masks personal information before it reaches the language model.
- Purpose limitation through architecture: AI agents only get access to the tools and data they need for their task. Guardrails and limited actions ensure the system doesn't operate outside its boundaries.
- 1 percent budget for security: OWASP Top 10 audits, regular security reviews. Not a major effort, but an important one.
This model also works especially well for companies with high confidentiality requirements. The combination of Azure contracts and pseudonymisation meets the standards of organisations with strict confidentiality obligations.
Humans stay responsible. That's not a compromise.
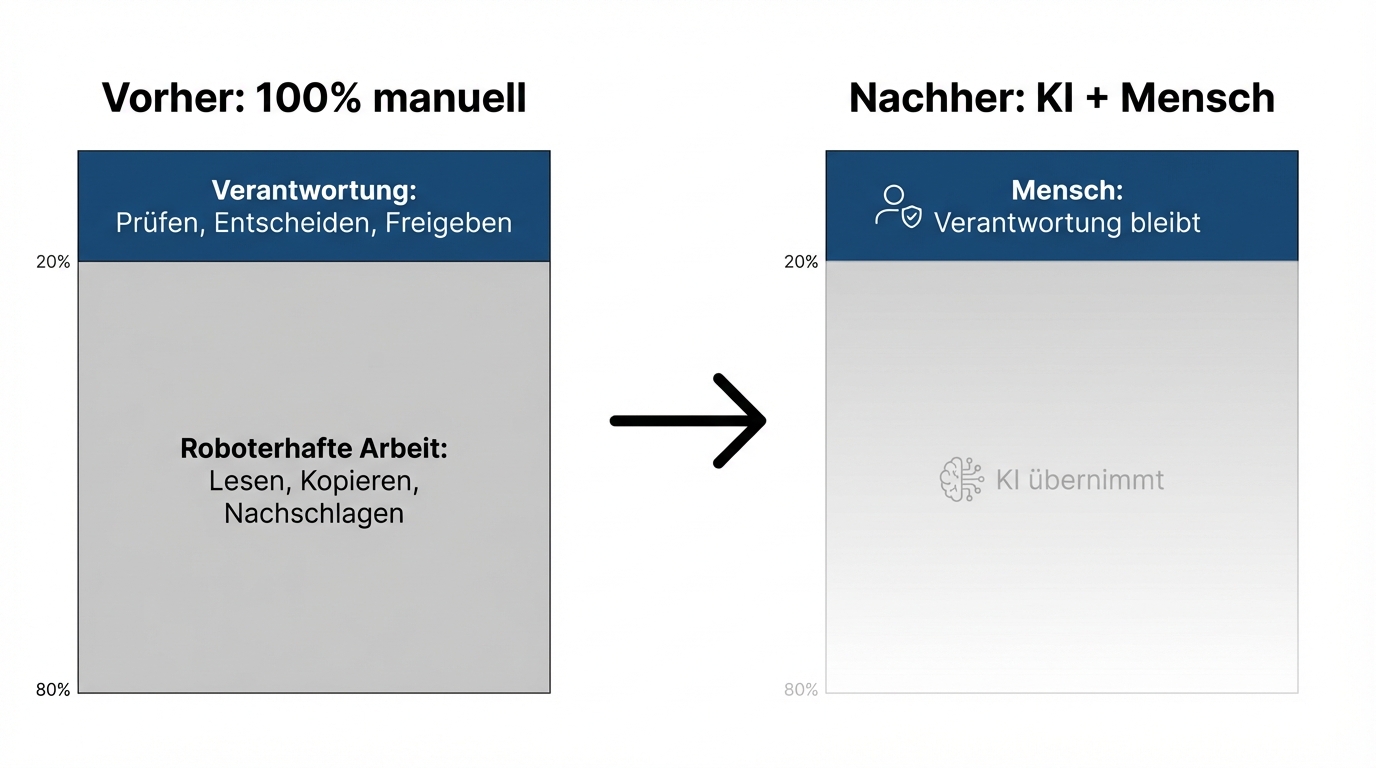
Human in the loop sounds like a restriction: the AI could work autonomously, but we don't let it out of caution. That's a misconception.
Human in the loop is the right architecture, not a cautious one. In the vast majority of business processes, 80 percent of the effort is robotic work: reading documents, compiling information, drafting outputs. The AI takes over that work. The remaining 20 percent is judgement, responsibility, decision-making. That stays with humans, and it becomes more important, not less.
A proposal that the AI has drafted needs to be signed off by someone who can take responsibility for it. A summary the system generates needs to be reviewed by someone who knows the context. That's not a brake. It's the architecture that builds trust -- with clients, with employees, and with regulators.
For the EU AI Act, this means concretely: high-risk applications require human oversight. If you work with human in the loop from the start, you automatically meet this requirement. If you build AI systems without human control, you'll have to retrofit later.
EU AI Act: what already applies and what's coming
Since 2 February 2025, the first obligations under the EU AI Act are in effect. For most mid-market companies, two points are relevant:
First: AI competence. Companies must ensure that employees who use AI systems are adequately trained. In practice, that means feedback workshops, prompting training, and understanding of capabilities and limitations. It sounds like a lot, but it's pragmatically solvable. Regular workshops that are documented meet the requirement.
Second: Transparency. Companies must disclose where AI is being used. Terms of use and internal policies must be updated. This, too, is architecture work, not a legal odyssey.
The most important advice: don't wait for the next wave of regulation. Lay the foundations now. If you start today with privacy by design, human in the loop, and transparent documentation, you're prepared for whatever comes next.
Who this works for
GDPR-compliant AI implementation is especially suited for companies with:
- Regular handling of personal data: Customer data, employee data, financial data as part of daily operations
- High confidentiality requirements: Companies that process sensitive data and want to use AI without compromising their confidentiality obligations
- Existing Microsoft infrastructure: If you already use Office 365 or Azure, you already have the framework agreement
- A concrete automation goal: A process that currently runs manually and should become faster, better, or cheaper with AI
What it takes: someone in the company who sees data privacy not as a blocker but as a shapeable constraint. The technical solutions exist. The contract structures exist. What's usually missing is the decision to use them.
The next step
You don't have to solve data privacy completely before starting with AI. You have to set up the architecture correctly. Contracts and system design take care of the rest.
If you want to know whether your planned AI deployment can be implemented in full GDPR compliance: get in touch. We'll review your specific use case and give you an honest assessment within a week, including an infrastructure recommendation and DPA structure.