
The most common question we hear before an AI project starts: "Who is liable if the AI makes a mistake?" The question is legitimate. But it leads in the wrong direction when used as a reason not to start at all.
The better question is: How do I make the risk measurable and controllable? Because that is exactly what's possible. Not by hoping for zero errors, but through methods that quantify, categorise, and reduce risk to an acceptable level.
Controlled autonomy instead of blind trust
The key lies in a simple distinction: not every decision carries the same risk. A miscategorised product is annoying but correctable. A wrong legal response to an end customer is a serious problem. Treating both with the same level of safeguards would be either negligent or paralysing.
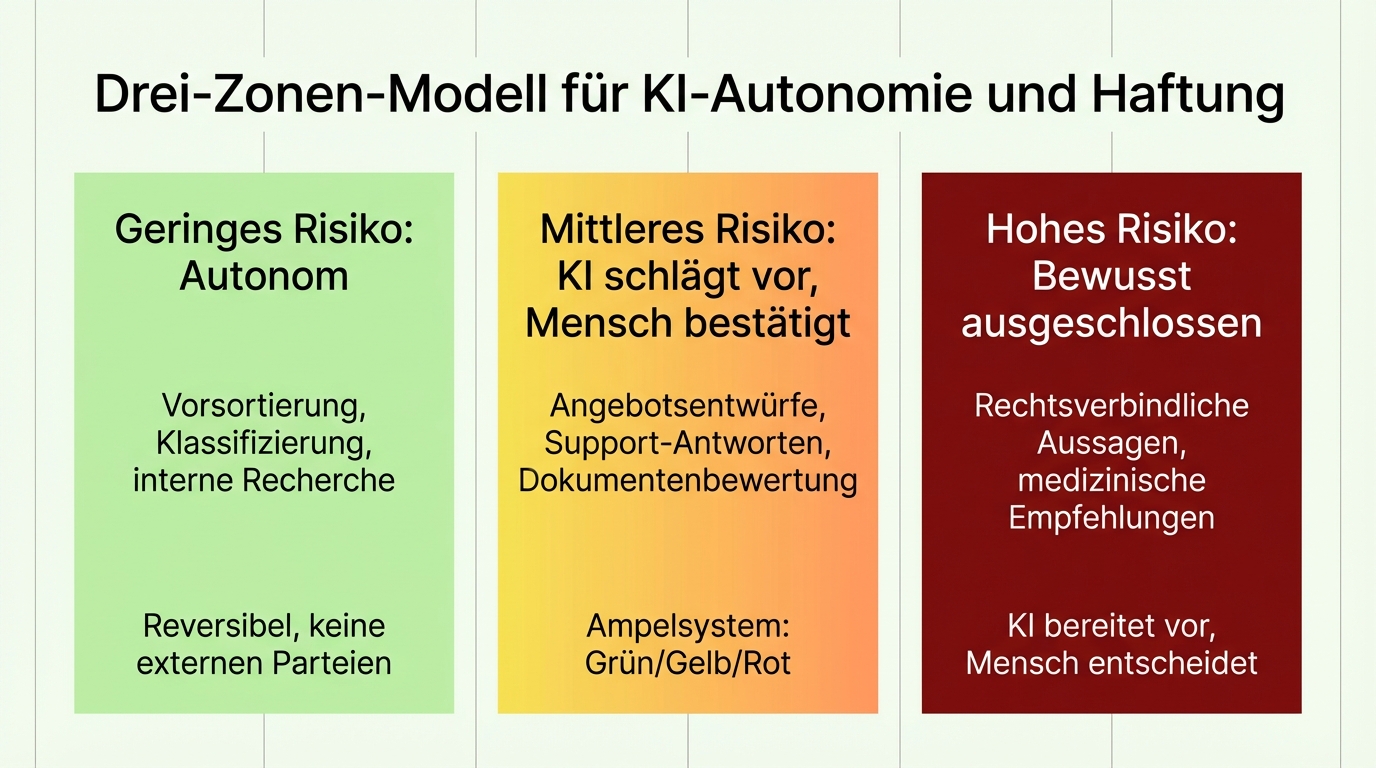
That's why we assess each request category individually, together with the client's domain experts, by one criterion: what is the worst that can happen? This yields three zones:
Low risk: Autonomous. The AI decides and acts on its own. Typical for pre-sorting, classification, internal research. If an error occurs, it's reversible and doesn't affect external parties.
Medium risk: AI proposes, human confirms. The traffic-light system: green means the human can accept directly. Yellow means the human should look more closely. Red means the human needs to start from scratch. This turns thousands of cases into perhaps a hundred that truly need human attention.
High risk: Deliberately excluded. Some decisions stay with the human. Legally binding statements, medical recommendations, safety-critical approvals. The AI's value here lies not in the decision, but in the preparation: gathering information, structuring options, drafting outputs.
A concrete example: for an automated customer support system, we trained on 400 real queries to determine which categories may be answered autonomously and which may not. The criteria: no data loss, no data protection incident, no unauthorised disclosure. What the AI cannot classify with confidence is escalated to a human.
Measure the risk, don't guess
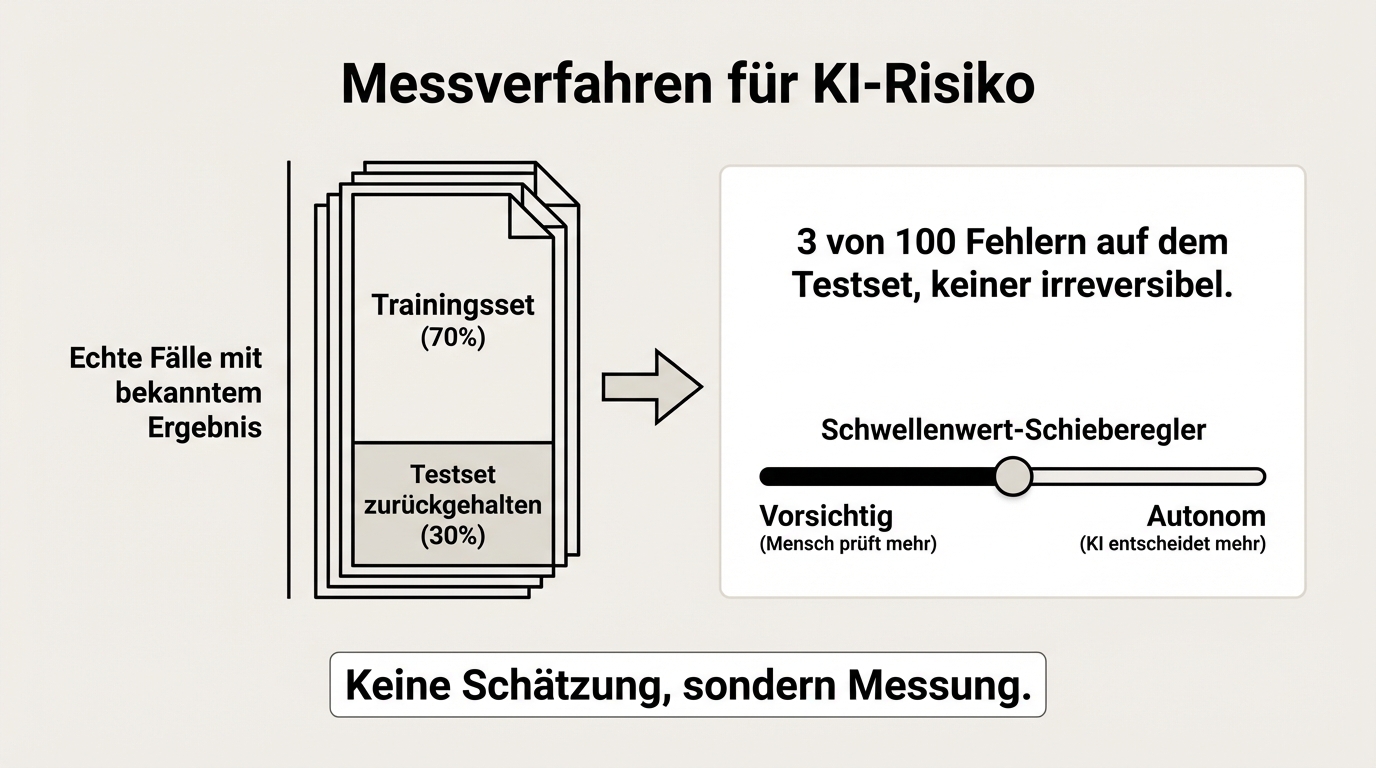
"The AI sometimes makes mistakes" is not a useful statement. Useful is: "The AI makes an error in 3 out of 100 cases for this document type, and in none of those cases is the error irreversible."
That is exactly the kind of statement we can make. For every use case we build a reference dataset: real cases where the correct result is known. Part of it is used for training, part is held back. On the held-back portion we measure the error rate before the system goes live. The result is not an estimate but a measurement.
This also means we can objectively state at which threshold the system may decide autonomously and from which point a human must intervene. The threshold is set so that no costly errors occur. Better too cautious than too aggressive.
This methodology is not new. It mirrors what classical quality assurance has practised for decades: sample testing, confidence intervals, defined error tolerances. Only now the testing happens automatically, on every single case, not just on a sample.
From "always check" to "controlled trust"
It starts with parallel operation. The AI produces a draft, the human reviews every result, corrects where necessary, and approves. This is the introductory phase in which the system learns and the human builds trust.
"The first two months I slept nervously," says one project lead about the first fully autonomous customer service bot. "Checked the results every day. At some point I realised: it works." That honest nervousness is not a sign of weakness but of responsibility. Anyone who isn't nervous hasn't understood the stakes.
After the introductory phase, trust can expand step by step, backed by data. If over weeks the alignment between AI output and human correction increases, you can raise the threshold for autonomous decisions. Not because you hope it works, but because you've measured it.
The goal is not to replace the human entirely. It's to deploy the human where they're truly needed: on the difficult cases, the exceptions, the decisions that require judgement. Not on the routine that eats up 80 percent of the day.
Who is liable? A clear allocation
Responsibility splits across three levels:
Technical and content responsibility: With the service provider. We ensure the system works correctly, the sources are up to date, the thresholds are set properly, and quality assurance holds. If an error traces back to our work, we bear the consequences.
Legal responsibility: With the client. The client decides which results to use, approve, and communicate externally. The AI informs, recommends, prepares. The decision on whether and how a result is used stays with the human.
Quality commitment: Measurable and traceable. Every AI generation leaves a complete trail: which prompt was used, which sources were consulted, which decision the model made. When something goes wrong, the cause can typically be identified within hours. Experience shows it's roughly half prompt-related, half source-related, almost never the technology itself.
This allocation is not fine print but a deliberate architectural decision. It ensures that technical quality is measurable, the business decision stays with the human, and both sides know what they are responsible for.
The right benchmark
Most discussions about AI liability compare the AI to perfection. The right comparison is different: the AI against the current process.
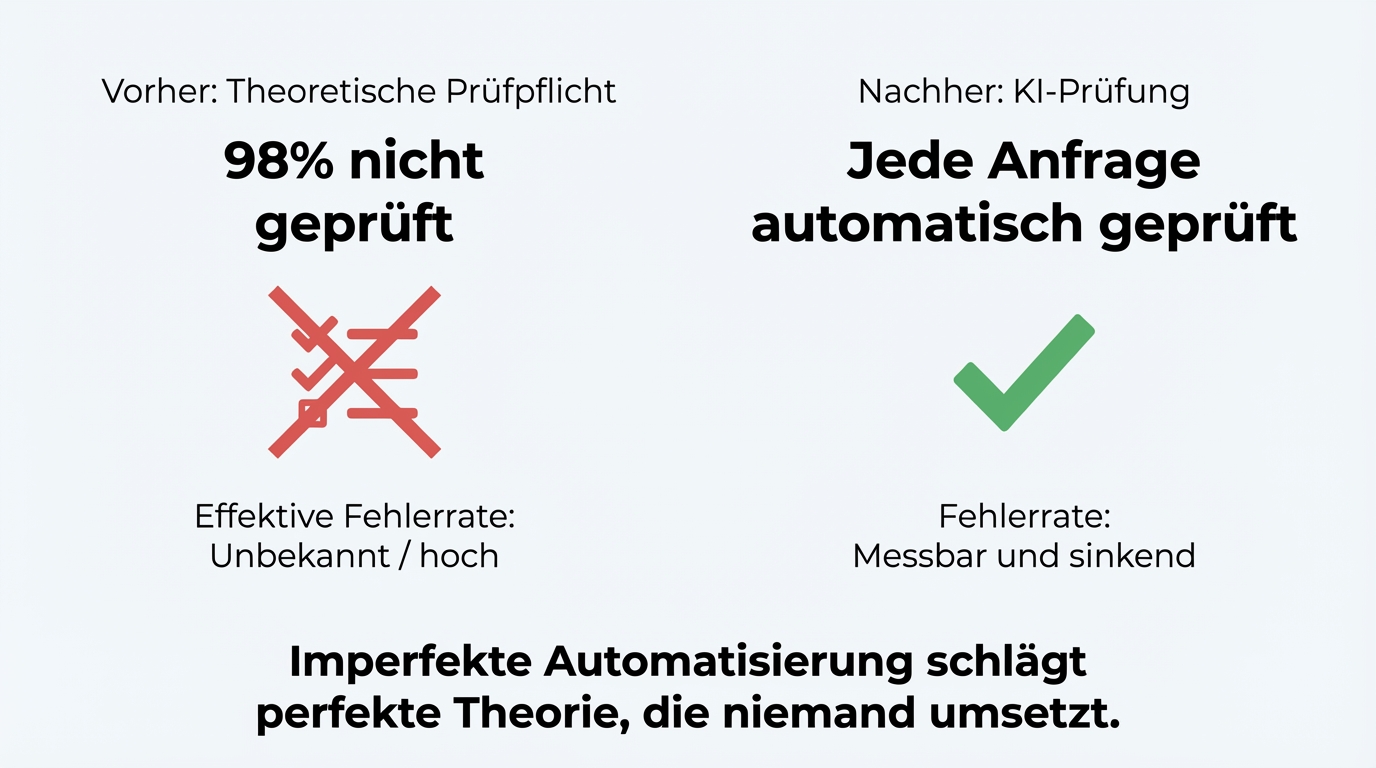
At one company, incoming requests were checked for completeness before processing. In theory. In practice, the check was skipped in 98 percent of cases. "Takes two minutes, but colleagues just don't do it." Now the AI automatically checks every request. Yes, it occasionally makes errors. But even with a 2 percent error rate, the system is dramatically better than the starting point: no check at all.
If the question is "Is the AI perfect?", the answer is no. If the question is "Is the process better with AI than without?", the answer in every project we've seen is: unambiguously yes.
The next step
Bring a specific process where you're considering AI but have liability concerns. We'll show you what risk-based categorisation looks like applied to your case, which parts can run autonomously, and where the human stays in the loop. In 60 to 90 minutes you'll have a clear picture -- not just of the technical possibilities, but also of the responsibility allocation.