
A 400-page tender lands on the desk. The deadline is running. Three people need two weeks to read everything, filter out the relevant requirements, and prepare a decision. Meanwhile, the other tenders sit untouched.
This problem can be solved -- but not by copying 400 pages into an AI tool and hoping for a summary. Instead, it takes a multi-stage analysis process that mirrors how an experienced domain expert works: first filter the volume, then go deep on the relevant sections, then present the results in a structured format.
The difference: reading is not understanding
What most AI tools do: they read a document and summarise it. That's useful, but it doesn't solve the actual problem. The value doesn't lie in compressing 400 pages into two. It lies in extracting concrete action items from 400 pages of running text: which requirements must be met? Which deadlines apply? Which hidden conditions are buried in the appendix on page 380?
That requires structuring, not summarisation. Unstructured text becomes obligations, deadlines, responsibilities, and assessments. That is the real technological breakthrough: not reading, but converting running text into actionable data.
Multi-stage instead of brute force
A domain expert doesn't read 400 pages linearly. They skim the table of contents, identify the relevant sections, read those carefully, and draw cross-references to other documents. That's exactly how a well-configured AI analysis works:
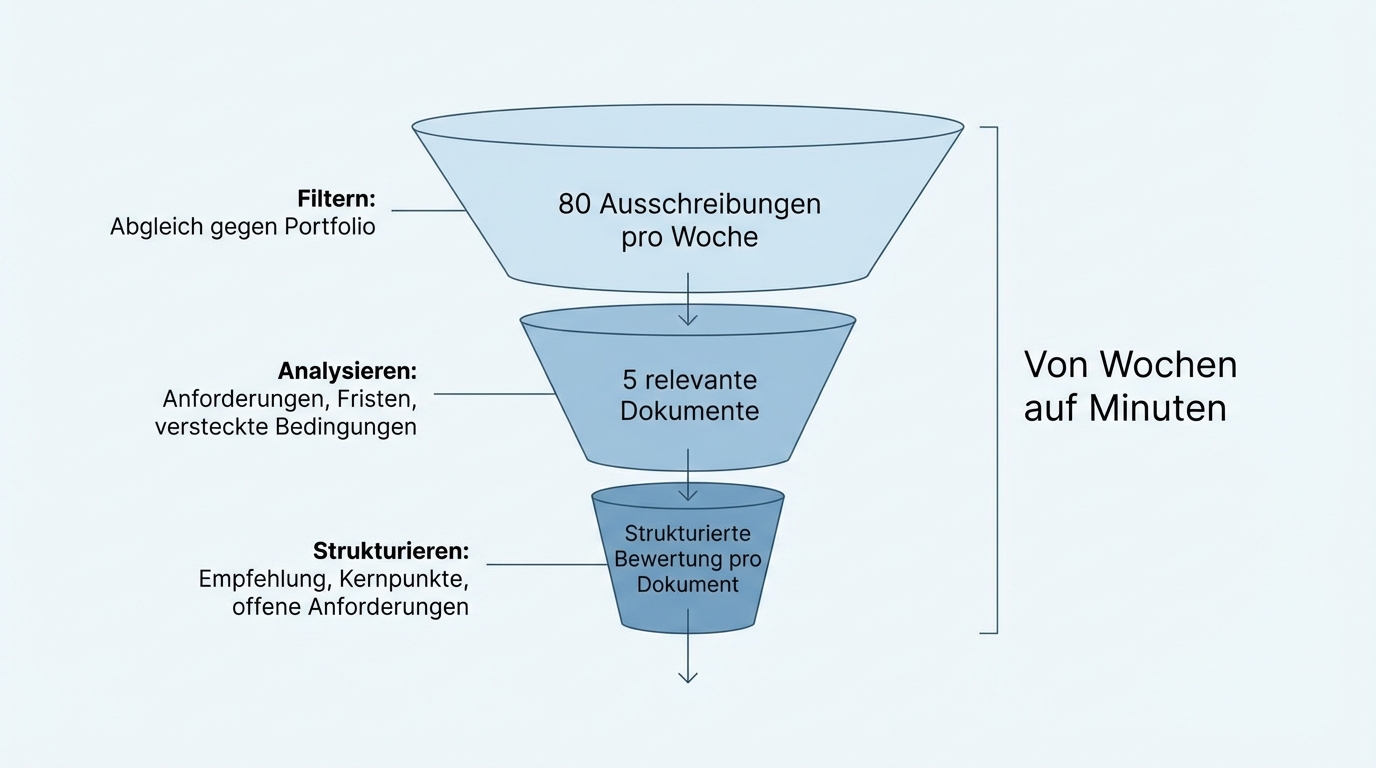
Stage 1: Filter. The full set is matched against the company's own portfolio or requirements profile. Of 80 incoming tenders per week, perhaps five survive the first filter as genuine fits. The other 75 are sorted out with a brief rationale. That saves the time previously spent on manual screening.
Stage 2: Analyse. The relevant documents are worked through in detail. The AI identifies line items, requirements, deadlines, and hidden conditions. Not only in the obvious structure, but also in appendices, footnotes, and cross-references between documents. It's precisely these hidden requirements that get missed in manual processing, because nobody reads 400 pages line by line.
Stage 3: Structure. The output is not running text but a structured presentation: an assessment (fit / no fit), a summary of the key points, a list of open requirements. In a format that a decision-maker can absorb in a few minutes.
Using this approach, one company improved its line-item recognition in specifications from an initial 20 percent to over 85 percent. Not through a better model, but through the right decomposition of the problem into sub-steps.
The AI doesn't have to be perfect
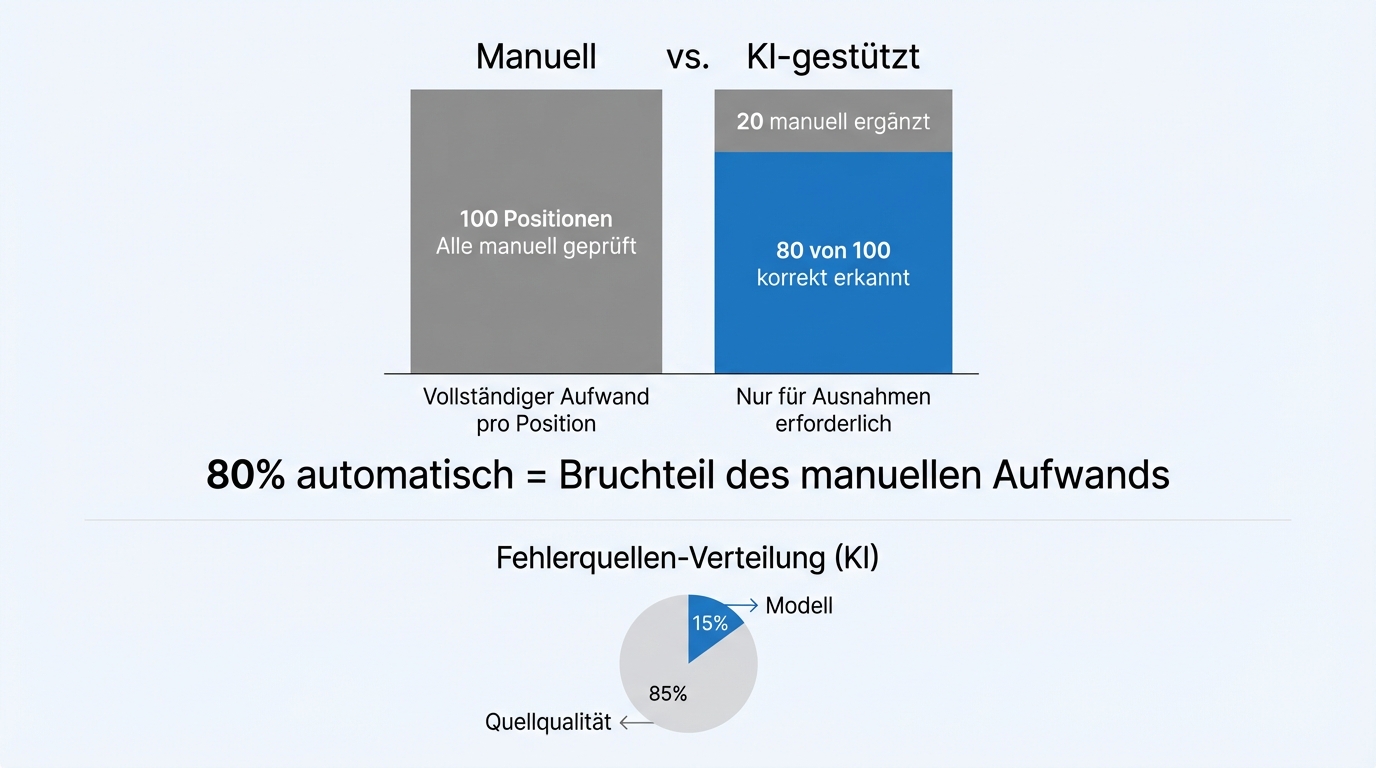
A common misconception: the AI must reach 100 percent accuracy before you can use it. Practice shows the opposite. The domain experts who work with these systems say: "If the scoring isn't perfectly accurate, that's not a problem. What matters is that the pre-selection is right."
80 percent accuracy in pre-selection means: out of 100 relevant line items, the AI correctly identifies 80. The remaining 20 are manually added by the domain expert. That's still a fraction of the effort previously needed for fully manual processing.
Whether the AI is at 80 or 90 percent can be measured objectively. For each document type, a reference dataset is created where the correct result is known. Accuracy is measured against it and communicated transparently. Not promises -- measurements.
Where accuracy falls short, the cause is rarely the AI itself. In the vast majority of cases, it's the sources: poor formatting, missing metadata, copy-protected PDFs, inconsistent document structures. Input quality determines output quality.
Not just one-off analysis: ongoing monitoring too
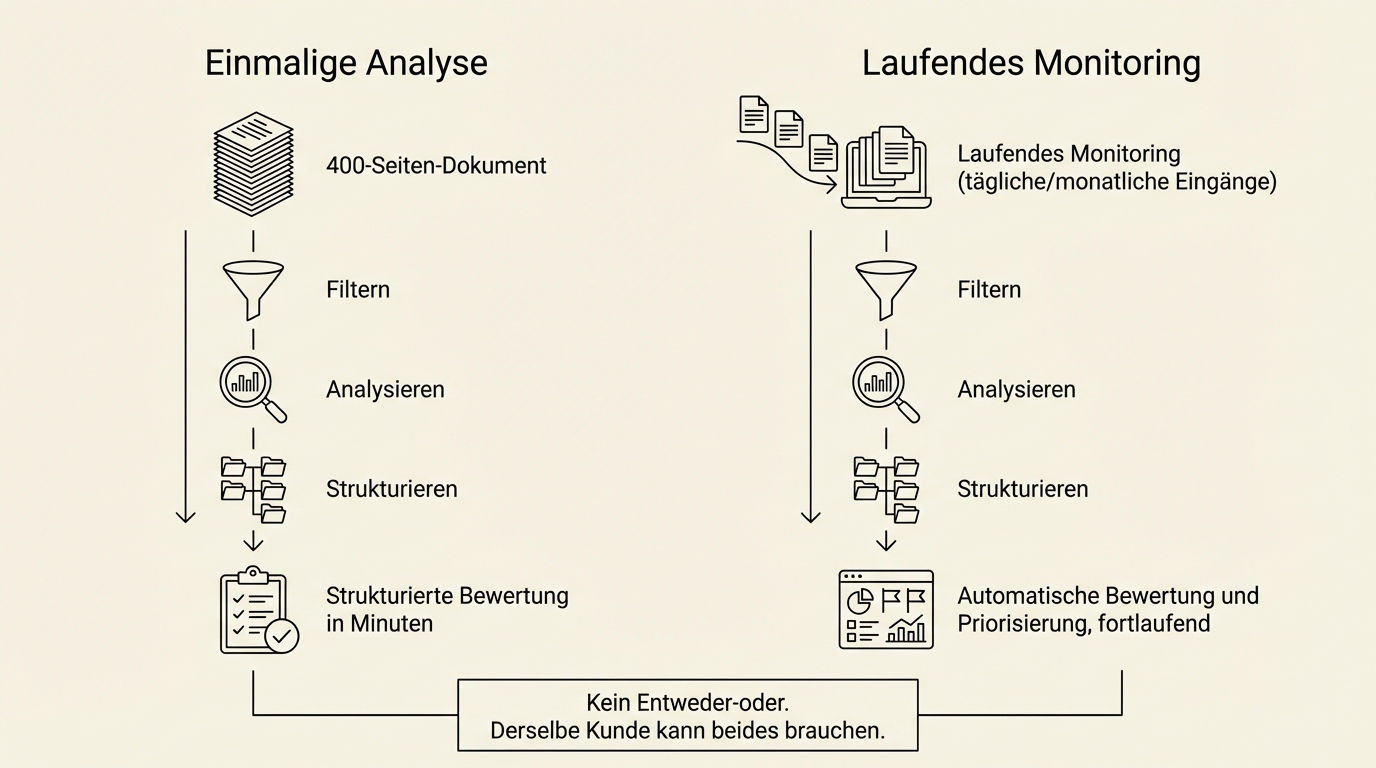
Beyond the one-off analysis of individual documents, there's a second use case: continuous monitoring of document flows.
One company has all new public tenders automatically downloaded, assessed, and prioritised every day. The relevant tenders land in the sales team's inbox with a brief assessment. Instead of two weeks of processing time, it takes minutes.
Another company monitors thousands of legal documents for changes: new legislation, repealed regulations, national implementations of EU directives. Monthly reports show what has changed and what that means for their own obligations.
One-off analysis and ongoing monitoring are two parallel offerings, not an either-or decision. The same client can have both needs.
What the AI needs to work
Three prerequisites determine the outcome:
A domain expert who sets the direction. The AI cannot decide on its own what "relevant" means. A domain expert defines the criteria: which tenders fit our portfolio? Which requirements are mandatory, which are optional? This direction-setting happens once at the start and is then applied by the AI across thousands of documents.
Representative sample data. Ten to twenty documents where the correct result is known. From these, the reference dataset is built against which the AI is calibrated and measured. Not hundreds, not thousands. A manageable set that covers the typical cases.
Access to the documents. The documents must be machine-readable. For well-structured digital documents, that's trivial. For scanned PDFs, copy-protected files, or handwritten notes, it gets more involved -- but solutions exist for those too.
An important note: where documents are well-structured (standardised forms, XML formats), we use rule-based extraction, not AI. AI is deployed where documents are unstructured, inconsistent, or fragmented. The two approaches complement each other.
What this changes in practice
The time savings are real, but they're only the most obvious effect. What else changes:
Nothing gets overlooked. Hidden requirements on page 380, an appendix with deviating conditions, a deadline buried in running text instead of the summary table. The AI searches systematically, not selectively.
Decisions happen faster. When a decision-maker receives a two-page structured assessment with a clear recommendation instead of a 400-page document, turnaround time drops from days to hours.
Capacity grows without headcount. Whether 10 or 80 tenders come in per week: the effort no longer scales linearly with volume. The team works on the relevant cases, not on pre-sorting.
The next step
Describe the process that's causing you headaches today: evaluating tenders, reviewing contract documents, monitoring compliance requirements. In a joint meeting, we'll give you a concrete assessment of whether and how the multi-stage analysis can be applied to your case, what effort is realistic, and what results you can expect.